
Czujnik ciśnienia 3408560 dla Cummins QSK Silnik z silnikiem Diesla


Bliższe dane
Typ marketingu:Gorący produkt 2019
Miejsce pochodzenia:Zhejiang, Chiny
Nazwa marki:Latający byk
Gwarancja:1 rok
Część nr:3408560
Typ:czujnik ciśnienia
Jakość:Wysokiej jakości
Świadczona usługa po sprzedaży:Wsparcie online
Uszczelka:Neutralne pakowanie
Czas dostawy:5-15 dni
Wprowadzenie produktu
Zgodnie z różnymi metodami przetwarzania danych istnieją trzy architektury systemu fuzyjnego informacji: rozproszony, scentralizowany i hybrydowy.
1) Rozproszone: Po pierwsze, oryginalne dane uzyskane przez niezależne czujniki są przetwarzane lokalnie, a następnie wyniki są wysyłane do Centrum Fuzji Informacji inteligentnej optymalizacji i kombinacji w celu uzyskania ostatecznych wyników. Dystrybucja ma niski zapotrzebowanie na przepustowość komunikacji, szybkość szybkiej obliczeń, dobrą niezawodność i ciągłość, ale dokładność śledzenia jest znacznie mniejsza niż w przypadku scentralizowanego. Rozłożona struktura fuzyjna można podzielić na rozproszoną strukturę fuzyjnej z sprzężeniem zwrotnym i rozproszoną strukturą fuzyjną bez sprzężenia zwrotnego.
2) Centralizacja: centralizacja wysyła surowe dane uzyskane przez każdy czujnik bezpośrednio do centralnego procesora w celu przetwarzania fuzji, który może zrealizować fuzję w czasie rzeczywistym. Jego dokładność przetwarzania danych jest wysoka, a jego algorytm jest elastyczny, ale jego wady są wysokimi wymaganiami dla procesora, niskiej niezawodności i dużej objętości danych, więc trudno jest to zrozumieć;
3) Hybryda: W hybrydowym fuzji fuzji informacji o wielu czujnikach niektóre czujniki przyjmują scentralizowany tryb fuzji, a reszta przyjmuje rozproszony tryb fuzji. Hybrydowe ramy fuzji mają silną zdolność adaptacyjną, uwzględnia zalety scentralizowanego fuzji i dystrybucji oraz ma silną stabilność. Struktura trybu fuzji hybrydowej jest bardziej skomplikowana niż w pierwszych dwóch trybach fuzji, co zwiększa koszt komunikacji i obliczeń.
Kalman Filter (KF)
Proces przetwarzania informacji przez filtr Kalmana jest na ogół prognozą i korektą. Jest to nie tylko prosty i konkretny algorytm, ale także bardzo przydatny schemat przetwarzania systemu w roli technologii fuzji informacji o wielu czujnikach. W rzeczywistości jest podobny do metod przetwarzania danych informacyjnych w wielu systemach. Zapewnia skuteczne statystyczne optymalne oszacowanie dla połączonych danych za pomocą matematycznych iteracyjnych obliczeń rekurencyjnych, ale wymaga niewielkiej przestrzeni do przechowywania i obliczeń, więc jest odpowiedni dla środowiska o ograniczonej przestrzeni i prędkości przetwarzania danych. KF można podzielić na dwa typy: rozproszony filtr Kalmana (DKF) i rozszerzony filtr Kalmana (EKF). DKF może sprawić, że fuzja danych jest całkowicie zdecentralizowana, podczas gdy EKF może skutecznie przezwyciężyć wpływ błędów przetwarzania danych i niestabilności na proces fuzji informacji.
Zdjęcie produktu

Szczegóły firmy







Zaleta firmy
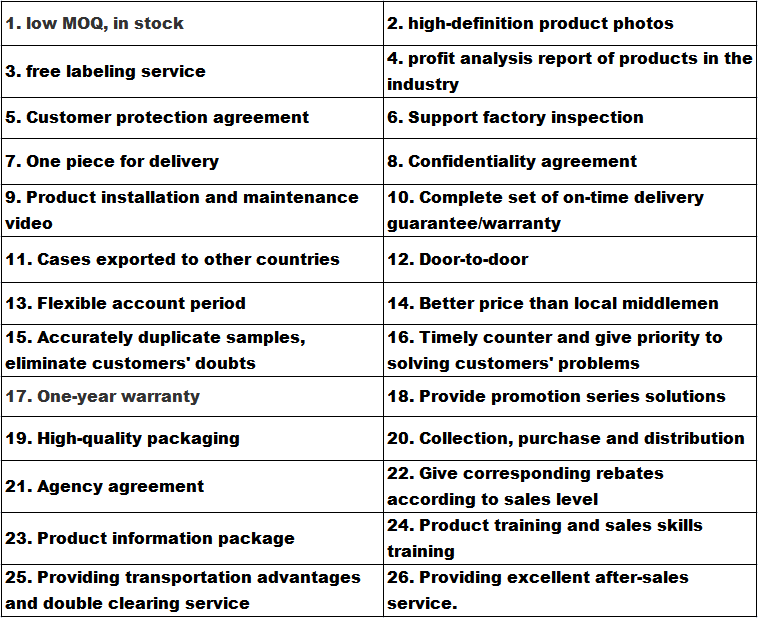
Transport

FAQ

Powiązane produkty








